Does anyone use text-based web browsers?
I don’t know much about the feature differences, but some interesting ones are:
- lynx
- links (runs JavaScript?)
- elinks
- w3m (displays images in the terminal)
- browsh (renders JS and images)
lynx
I used to use lynx for basic web scraping (lynx --dump) before I learned other ways. Most websites used regular HTML for content back then.
Example: extracting the URLs of search results:
$ lynx --dump https://www.duckduckgo.com/?q=lynx \
| perl -ne 'if (m/\s+[0-9]+.\s+.*=(http.*)/s) { print "$1"} '
links
links works like lynx but preserves more of the layout. I haven’t used it much.
elinks
elinks tries to preserve some of the layout and colors. It doesn’t do the best job with images, but I’ve used it to browse the web from my remote servers.
elinks can dump the output in a similar way to lynx, but it also outputs links to static assets:
$ elinks -dump https://codeselfstudy.com \
| perl -ne 'if (m/\s+[0-9]+.\s+(http.*)/s) { print "$1"} ' \
| sort \
| uniq
browsh
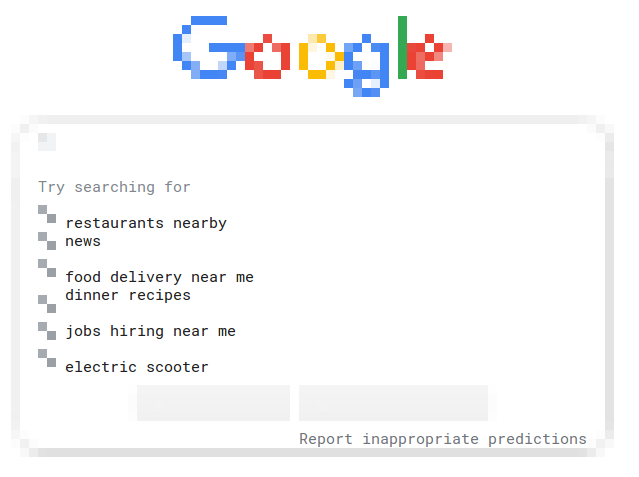
I tried browsh with Docker today:
$ docker container run --rm -it browsh/browsh sh
Then after it downloads, type this:
$ ./browsh
You can click on links to visit them or use ctrl+l to enter a URL. To quit, use ctrl+q.
I found that one here:
